Why your own voice works better — the quiet psychology of hearing yourself
Hearing your own voice changes how a self-statement lands. Not because it's louder — because the brain processes self-voice as identity-relevant data. Here's what 30 years of research on future-self continuity, self-distancing, and voice recognition actually shows.


Most affirmation apps treat the voice you hear as a delivery detail — a pleasant actor, a clean text-to-speech, a meditation teacher you'll forget the name of by Thursday. Thirty years of psychology research suggests they have the priority inverted. The content of a self-statement matters. The voice it arrives in matters more than that — especially when the voice is yours. Here is what the studies actually say, why it isn't quite "neuroscience says affirmations work," and what to do with it tomorrow morning.
A self-statement delivered as audio, in the listener's own recorded or modeled voice, designed to engage the brain's self-recognition systems rather than its general language-comprehension systems. The mechanism is less about content than about who the brain decides is speaking.
What "hearing yourself" actually does in the brain
When you read a sentence silently, your brain processes it as language — a stream of symbols to interpret. When someone else reads it aloud to you, you process it as social input — a person communicating something. When you hear it in your own voice, the brain does something different again: it activates regions associated with self-referential processing.
The classic neuroscience finding here comes from work on self-affirmation theory. Cascio and colleagues used fMRI to show that affirming a core value activates the ventromedial prefrontal cortex (vmPFC) and ventral striatum — areas associated with self-evaluation and reward.Cascio et al. 2016 The activation is stronger when the affirmation is about the self and stronger still when it is processed as personally relevant — not as someone else's claim about you.
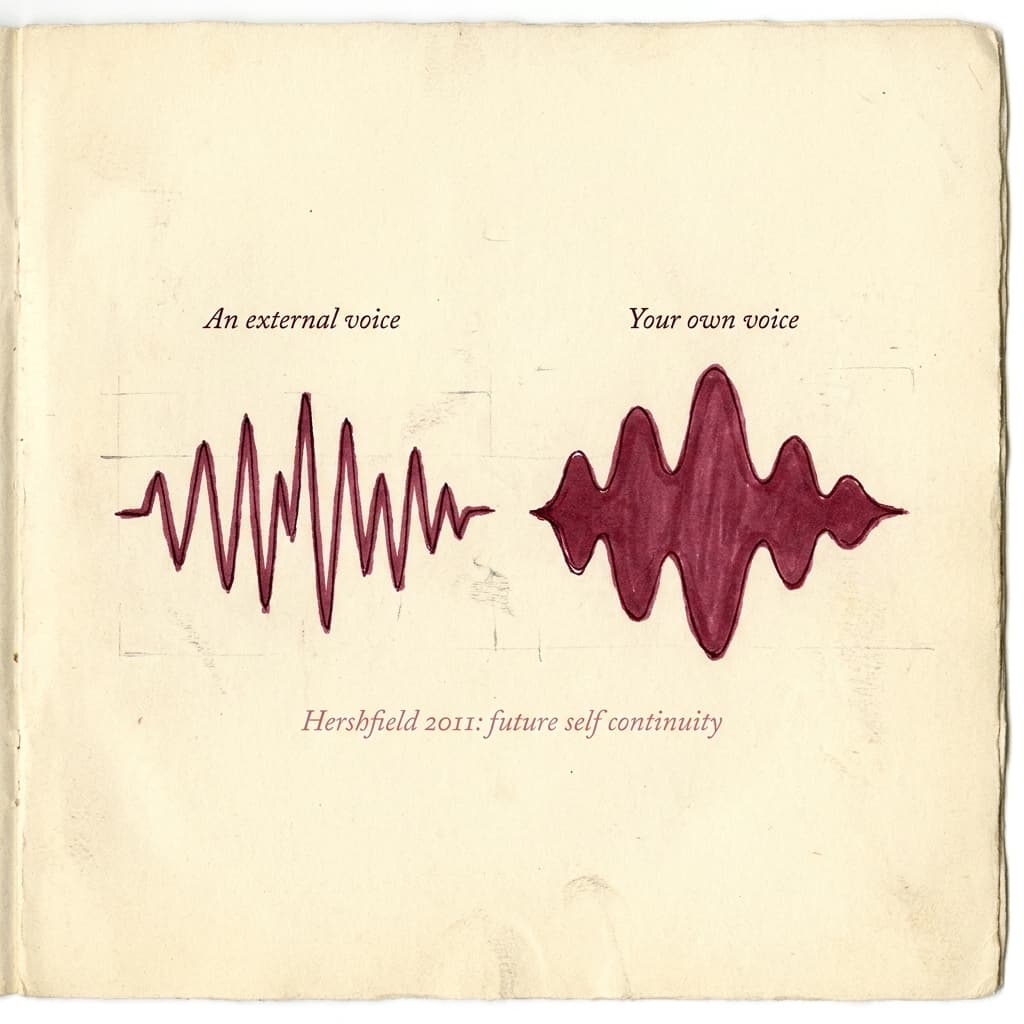
Voice is one of the most reliable cues the brain uses to decide what is "personally relevant." Studies of voice recognition show that hearing your own voice — even a recording you've never listened to — activates self-related networks differently from hearing a stranger.Kaplan 2008 Your brain has a category called me, and audio of your own voice gets filed under it almost reflexively.
This is not the same as saying your voice is more truthful than other voices. It says only that the brain stops doing the work of deciding whether to take the statement personally. Whether the statement is useful once it's filed under me is a separate question — and one we'll come back to in the section on when this backfires.
The future-self continuity effect — why hearing yourself a year ahead matters
The single most-cited piece of research behind voice-based self-talk comes from Hal Hershfield's lab at UCLA. In a 2011 study published in the Journal of Marketing Research, participants who were shown an age-progressed image of themselves — a digital rendering of who they'd look like in 30 or 40 years — allocated, on average, 30% more to a retirement account than participants shown a current image.Hershfield et al. 2011
The mechanism Hershfield proposed — future-self continuity — is that humans tend to treat their future selves as strangers. We save less for that stranger, exercise less for that stranger, take fewer career risks on her behalf. When the brain experiences the future self as the same person, the math changes. We start investing in her the way we invest in someone we know.
Voice is, in principle, an even stronger lever than imagery. Vision activates self-recognition. Voice activates self-recognition and identity-relevant audio processing and the broader narrative-self system that connects past, present, and future memory.McAdams & McLean 2013 When you hear yourself say something — particularly something you don't quite believe yet — the brain has fewer doors to close on it.
This is the strongest argument I can make for voice as the delivery format for self-talk. Imagery of your future self is good. Text in her voice is better. Audio in her voice, delivered into your ears in the morning when the brain is most plastic, is, on the evidence, the strongest version we currently know how to build.
Self-distancing — why second-person works (and how voice amplifies it)
There's a separate research line, distinct from Hershfield's, that matters here. Ethan Kross and colleagues at the University of Michigan have spent more than a decade studying self-distancing — what happens when you talk to yourself in the second or third person rather than the first.
The findings are remarkably stable across studies: addressing yourself by name ("You'll be okay, Maddie") or in the second person reduces anxiety, improves performance on stressful tasks, and shortens recovery from rumination.Kross et al. 2014 Brain imaging by Moser and colleagues showed lower activation in the medial prefrontal cortex — a marker of self-referential distress — when participants reflected on a negative experience in the third person.Moser 2017
What does this have to do with voice? Self-distancing works because it gives the speaking self a small amount of separation from the experiencing self. A voice that addresses you by name is that separation, embodied in audio. Hearing "You'll find your way through this, Maddie" in your own voice, addressed to you, is a Kross-style intervention with the volume turned up. It is also exactly the format almost no consumer app delivers.
The voice you record vs. the voice that's cloned
A small but practical question: does it matter whether you record yourself saying the affirmations, or whether the affirmations are rendered in a cloned model of your voice?
The honest answer is that there is no peer-reviewed study comparing these two formats directly, because consumer-grade voice cloning is too new for the research to have caught up. What we can do is reason from what the existing research tells us.
A raw recording of yourself reading affirmations does several things well. It is unambiguously you. It carries your specific timbre, your hesitations, your morning tone. It is also limited: you have to record every new affirmation yourself, you can't generate fresh language each day, and on the morning you most need to hear something kind, you are the least likely to sit down and record it.
A cloned voice — a model trained on a short sample of your speech, capable of rendering new text in your acoustic signature — preserves the self-recognition cue (the brain still files the audio under me) while making the practice sustainable. The trade-off is acoustic fidelity. A good model captures your timbre but smooths your distress, which, depending on what you are trying to do, is either a feature or a bug.
For a daily morning practice, the trade-off generally favors the cloned voice — not because it sounds better (it doesn't, quite), but because the morning you most need a steady voice is the morning your own voice is least steady. A good model gives you yourself on a calmer day, which is closer to the voice your future self would use anyway.
This is where the consumer-app category is currently weakest and where the academic research most under-serves us. We need direct A/B comparisons between recorded affirmations and cloned-voice affirmations across populations with high and low self-esteem, against control conditions of text-only delivery. Until then, the principled position is: voice is better than text, your voice is better than a stranger's, and a well-trained model is plausibly better than a single recording for daily use.
The voice you hear at the moment you most need it should sound like yourself on a day you could afford to be kind.
When this works — and when it doesn't
The literature on voice and self-affirmation is overwhelmingly positive, but there is one finding that complicates the picture, and I want to put it on the table clearly.
In 2009, Joanne Wood and colleagues at the University of Waterloo ran a study that has since become a touchstone for anyone designing affirmation interventions. Participants with low self-esteem who repeated the declarative statement "I am a lovable person" reported worse mood afterward than a control group — worse, not better.Wood 2009 The mechanism: when the brain holds a self-concept (I am not lovable) and is asked to repeat a directly contradicting statement, it doesn't resolve the gap by updating the concept. It resolves it by deepening rumination on the evidence the concept was based on.
This finding does not go away when you change the voice from external to internal. If anything, hearing yourself say "I am a lovable person" in your own voice when you can't believe it may make the dissonance louder, not softer — you can't dismiss the speaker as someone who doesn't know you.
The workaround Wood's team and later researchers proposed is conditional phrasing. "I am learning to value myself" does not trigger the same dissonance, because it does not claim what isn't yet true. It claims the direction of travel, which the brain can accept.Cohen et al. 2003
This is why every affirmation that runs through HerDay is run through what we call a conditional pass. If your intake suggests a loud inner critic, declarative phrasing is automatically softened — "you are kind" becomes "you are learning to be kinder to yourself." The voice does not change. The grammar does.

What to actually do tomorrow morning
If you take one practice from this article, take the following: tomorrow morning, before you open any app, before you check the news, before anyone speaks to you, address yourself by name for one sentence. Out loud, if you can. "Today, [your name], you don't need to perform. You only need to show up."
That sentence — short, addressed, present-tense, conditional where it needs to be — is the simplest version of what thirty years of research suggests you should be doing. Adding voice doesn't change the principle. It changes the volume. Adding your own voice doesn't change the volume. It changes whose words the brain hears them as.
The reason we built HerDay around voice is not that we discovered a new psychological mechanism. It is that the existing mechanisms — Steele's value-touching, Kross's self-distancing, Hershfield's future-self continuity, Wood's conditional phrasing — combine into a particular shape when delivered as audio in the listener's own voice. That shape happens to be a 30-second morning ritual. We didn't invent it. We just listened to what the research has been quietly telling us for thirty years and put a microphone in front of it.
Do affirmations actually work? A 2026 evidence-based review
Affirmations work — but only the kind grounded in your existing values, and only when phrased to match where your self-esteem actually is. Here is what 30 years of psychology research shows, and where most apps get it wrong.
Letter to your future self — how to write one, and why it changes more than you'd think
A letter to your future self is a small, well-studied intervention with measurable effects on saving, self-care, and follow-through. Here is the research behind it, a 7-step method to write yours in 30 minutes, 12 prompts to start, and one common mistake that quietly undermines the whole point.
Your inner critic isn't telling the truth — she's reading old data
The inner critic feels like a verdict. The research says she's a reflex — a learned, protective voice repeating old data with high confidence. Here's what Neff, Gilbert, and Kross actually found, and what to do with her tomorrow morning that isn't 'silence her.'